Are experimental neuroscience studies becoming algorithm fodder?
What are you talking about?
A few months ago I was in San Francisco. I grabbed a trendy vegetarian brunch (complete with $8 cold pressed juice) with an old friend. He works at a tech consulting firm that is currently interested in how ‘datification’ will disrupt certain industries. ‘Datification’ is a silly pretend word but it represents the idea that many aspects of our everyday lives are now available as computerized data. Imagine (if you can) the olden days when you couldn’t search and sort through your list of friends or look at your phone to see how many calories you had burned that day. There are now many services that turn aspects of your life into data. ‘Datafication’ produces opportunities to analyze previously unavailable information to gain novel insights to the processes that produce it.
The tricky part is figuring out how to analyze this kind of data and how to integrate multiple analyses in a way that best suits your needs. This is an emerging field becoming known as data science. Some services that involve applying data science to newly available data are services such as online reputation management and digital marketing using social media data, and data-driven public health policy for large-scale health data. When Netflix recommends a move or an Uber driver picks you up, your data is being gathered and analyzed by some clever algorithms. Most of this data is so sparse and distributed that it will never be the Orwellian, fascist nightmare some people think it will; but this process, for better or worse, provides us new ways for us to interact with the world around us. Since its emergence, it has become clear that this process of ‘datafication’ and applications of data science have transformed how we live and how many businesses work.
Ironically, one of the few fields that has been slow to apply data science, is academic research. It is safe to bet that just as data science has changed many industries, data science will also change how we do research in the information era.
Can we ‘datify’ neuroscience?
Neuroscience, as a formal study, has been going on for about 100 years now. In that time there have been lots of great studies that link the complex biology of our brains to mental processes. By the nature of the scientific method, most experiments study how one variable affects another. For example, I just saw an experiment where there was a difference in activation in certain parts of the brain between depressed people and healthy people - the variables here being (1) depression and (2) activity in certain brain regions.
Alone this study doesn’t tell us much. It tells us an important link between depression, brain regions but that’s not enough to say anything meaningful about depression, brain regions or their interaction. However, when we synthesize many studies together, we can start to tell a coherent story about how our brains work and how they break using many many pieces of evidence like how Robert Supolsky does here:
The process of fitting a study into a larger story is very hard. It takes years of research to find meaningful papers and an unmeasurable amount of creativity to piece it all together and develop new understandings of the how our brains work. A google scholar search of papers about depression returns a little less than 3 million results. Robert Supolsky, the guy in that video, has spent his entire life working very hard to develop explanations of how mental disorders like depression work. Those of us new to the field are in trouble. Every day thousands of new pubMed articles are published. If I want to be a thorough scientist, do I have to read all of the neuroscience papers every day in addition to reading to catch up on 100 years of neuroscience? I really hope not.
Technology has taught us that there are often easier ways of combing through >3 million sources of data than doing it individually by hand. Search engines provide a crude way of doing this. Search engines keep track of where things are on the internet and give us the data that it thinks is most relevant to our searches. However, search engines only give us hints for where to find the info that we want. I want a knowledge engine for academia. I don’t want to search for something and find where it is, I want to know what it is.
It turns out that’s pretty hard for computers. It’s easy to make computers do math and perform tasks repeatedly but it’s hard to make them think ‘creatively’, tell stories, and explain things in a way that humans can understand. We’re a long ways away from making a computer think creatively but there are some clever algorithms that are ‘hacking’ this problem.
Brain Scanr
A case study in hacking neuroscience
When you go on a social media site like LinkedIn, it recommends friends that you might know. My boss’s project, BrainScanr analyzes neuroscience data in a similar way. With this tool, you can search for a neuroscienc-ey word like ‘depression’ or ‘dopamine’ and it scours the literature to find what other neuroscience terms are associated with yours. For example, we’ve known for a long time that people with Parkinson’s disease have lower levels of dopamine in the substantia nigra. If we search for Parkinson’s Disease on brain Scanr, we get this:
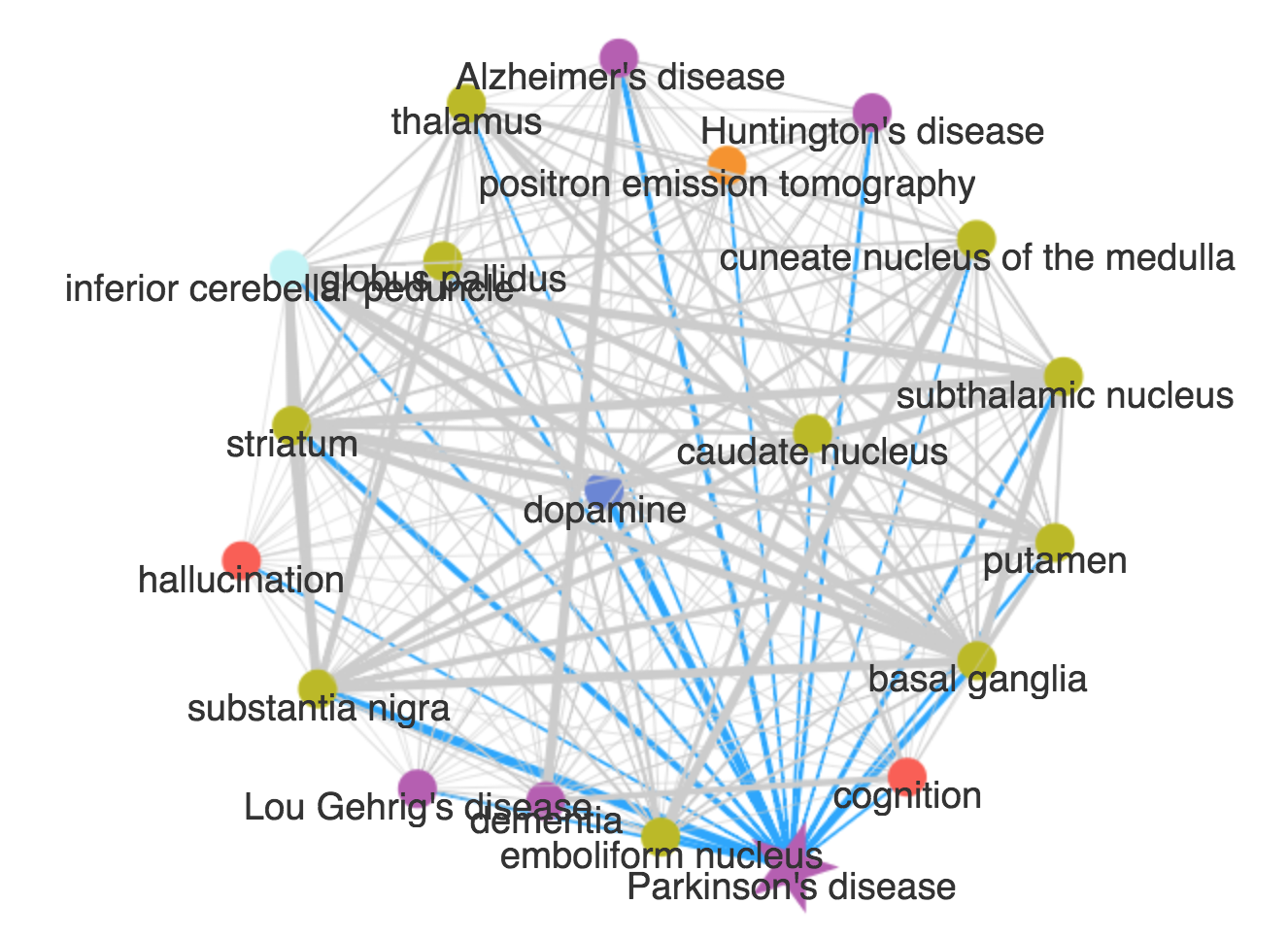
This web shows us all of the terms found in the literature that are found in the same papers as the words ‘Parkinson’s Disease’. We can see the strong links between dopamine, Parkinson’s Disease, and the basal ganglia - that is nothing special. The bigger story here is comes from the terms that we didn’t expect to see. I didn’t expect to see hallucinations on this figure. I wasn’t aware that hallucinations had anything to do with Parkinson’s but after a quick google search, it turns out some people with Parkinson’s disease sometimes have hallucinations and this is well documented in the literature. Maybe I should have studied harder in Dr. Koven’s cognitive psychology class - sorry Nancy. However, upon further inspection of this figure, I noticed that none of the brain regions involved in Parkinson’s disease are strongly linked to hallucinations! I wouldn’t have known this no matter how many times I tried to memorize the textbook.
Everybody who’s anybody knows that Parkinson’s disease has a lot to do with a malfunctioning dopamine circuit linking a couple of brain regions. However, the hallucinations Parkinsonian patients get don’t appear to be involved in the same Brain ScanR network. This means that either 1) hallucinations are related to these networks and we don’t see a link because nobody is studying it and publishing papers noting their interaction or, 2) Parkinsonian hallucinations come from a different problem in the brain that hasn’t been associated with Parkinson’s disease in the literature. In both cases, this indicates a gap in the research that should be filled.
This kind of analysis isn’t possible in a typical literature search - typing some words into the google scholar search bar. This kind of analysis tells us what to search for and what we should study. This computational algorithm was the means to providing a novel insight using data that has existed for years. Again, there are often thousands of papers published about any topic in neuroscience. This algorithm provides a way by which we can use the collective intelligence of the corpus of neuroscience research to produce unbiased research directions.
Other meta-analytical algorithms
Brain scanR is not the only project using data science in neuroscience. There are a few groups doing this kind of work and developing tools to do this kind of work. Most of these tools are in their infancy but it will be exciting to watch them develop.
Here are a few:
Project
|
Description
|
Link
|
Paper
|
NeuroSynth
|
Meta-analysis of what terms are associated with specific fMRI activation
| ||
Allen Brain Atlas
|
Genome-scale profiling of gene expression in human and rat brains.
| ||
NeuroElectro
|
Meta-analysis of brain-wide differences in neuron physiologies
|
in press
| |
DAVID
|
Gene classification via multiple-databases
| ||
NSABA
|
My amateur attempt at this
|
https://github.com/voytekresearch/laxbro/blob/master/Nsaba_Demonstration.ipynb
| someday... |
Do we need this?
We are currently facing a problem concerning ‘overflow’ in the scientific literature http://www.ncbi.nlm.nih.gov/pubmed/26365552?dopt=Abstract . Too much research is being published for anyone to keep up with. There are many possible solutions but I think the most attractive is automated meta-analysis. I think that automatic hypothesis generation is the next step in the scientific method. For all of human history, we have been limited by our own creativity and the time it takes to test our hypotheses. For the first time ever, technology now allows computational meta-analyses to algorithmically produce novel hypotheses and perform coarse tests on them. This is especially useful in neuroscience where we have to integrate a huge amount of knowledge across domains. A complete understanding of brains must span biochemistry to neural networks to psychology and it is unlikely that anyone, alone, will be able to understand the corpus of research in any of these domains. Most neuroscientists focus on one feature of one sub-domain. Computers allow us to build the scaffolding to connect the work of these researchers to build a self-consistent but multi-domain explanation of how brains work.
Scientific advancement doesn’t happen linearly, it happens in leaps in bounds (http://www.powells.com/biblio/62-9780226458120-0). This kind of analysis affords us the possibility of exponentially increasing the rate of scientific discovery by rapidly and iteratively producing hypotheses and testing them. Automation is the next logical step in the scientific method and we are just now witnessing the first generation of these tools.
Are experimental studies becoming algorithm fodder?
No, and sorry if I click-bait-ed you with this title. Experimental studies are definitely not only algorithm fodder. Experimental neuroscience is still producing tons of fruitful results on its own. Most importantly, we don’t know how to perform meta-analyses very well. While all of the tools I’ve mentioned do a pretty good job, they are nowhere near having the complexity required to do much without human supervision. Computational analyses can logically guide our thinking but they are nowhere close to replacing the human thinking required to keep science moving forward. Moreover, any hypotheses derived from computational analyses should be replicated with real experiments. Meta-analytical tools produce hypotheses, not answers. And any good scientist knows how important it is to challenge and test hypotheses.
What’s the point?
In research, like many other things, the whole is greater than the sum of its parts. The more we synthesize the work we do and the work that we have done, the more we can fill in the bigger picture together. Algorithmic neuroscience meta-analysis is in its nascency but as we’ve seen with industry, combinatorial data analytics has a tendency to produce unpredictable and epic possibilities to explore. The idea that this technique might have similar effects on science is itself, a hypothesis that we don’t have an answer for but I certainly hope there are lots of people excited to test this out as I am.
No comments:
Post a Comment